Storage Format
A VDS dataset is defined by a set of axes, each having a name, unit and number of samples, that determines the dimensionality (up to 6D) of the VDS, and a set of data channels, each having a name, unit and data format, that determine which values are stored for each position in the VDS. A VDS also has a base brick size (see below) and a setting for how many level-of-detail (LOD) downsampled versions of the data there are.
There is always at least one channel, the primary channel, and it always has the same dimensionality as the number of axes of the VDS. The VDS might also have additional channels, these channels can optionally ignore the first axis of the VDS and instead store a fixed number of values (most commonly a single value). Additional channels can also specify that they do not have LODs as it is not all data types that are meaningful to downsample.
The data in a VDS is organized into layers, which is the data for a specific channel with a specific LOD and a specific partitioning into chunks. Chunks are 3D bricks or 2D tiles that can be serialized using different compression methods (including no compression) and are stored as individual objects in the cloud, or in a container file. The VDS formats support multiple partitionings of the same data into chunks, e.g. the data can be stored as both 3D bricks and 2D tiles to allow for faster access to slices of the data at the cost of increased storage requirements.

An illustration of a VDS with two channels. The primary channel contains a 3D volume of seismic amplitudes. The samples are stored as 32-bit floating point values, and the data are partitioned into chunks (thick gridlines). There is also a 2D auxiliary channel which contains indicates if the trace is present or not. The channels may have different data format and compression method.
The format also specifies how metadata, key-value pairs pertaining to the VDS as a whole, is stored. There is a set of known metadata that applications using VDS for a specific purpose (e.g. to store seismic data) are expected to follow, both required metadata and additional optional metadata that can be used to store information that allows re-creating the original data (e.g. SEG-Y file or other proprietary formats) exactly.
The description of the partitioning of the data and all related metadata is encoded in the JSON format (The JSON Data Interchange Format, 2017), thus it can easily be interpreted using a variety of programming languages and technologies. Each chunk of data is serialized in one of several available binary serialization methods, all of which have open source deserialization code available.
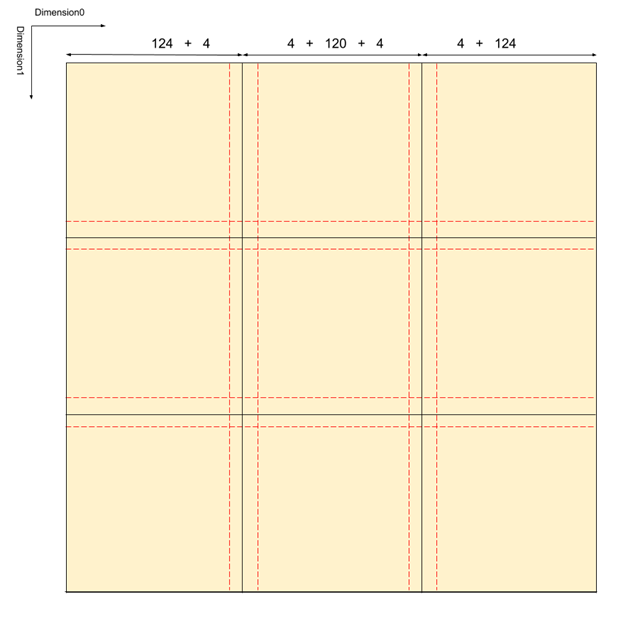
A 2D example of how bricks are laid out in a layer. In this example base brick size is 128 voxels, while both PositiveMargin and NegativeMargin are 4 voxels
Layers
Each multi-dimensional array of data is called a layer, there will be one layer for each partitioning of each LOD of each data channel in the dataset. The partitioning of a layer into 3D bricks or 2D tiles is done with respect to a dimension group which defines which dimensions of the multi-dimensional array are the 3 dimensions of the bricks. For example a 4D array can be partitioned into 3D bricks that are either including the 012 dimensions of the 4D array, or the 013 dimensions or the 023 dimensions or the 123 dimensions.
The name of a layer is formed by appending channel name + dimension group + LOD, and for the primary channel of the
dataset the channel name is omitted from the layer name. An example layer name is Dimensions_012LOD0 for the 012
dimension group of the primary channel at LOD 0. See figure_layers for an illustration of how a seismic
poststack dataset is organized.
Chunks
Chunk data formats supported include 32- and 64-bit floating point values, 8- and 16-bit unsigned integers with a scale and offset (which can be used to represent quantized floating-point values), 32- and 64-bit unsigned integers, and 1-bit Boolean values. Null/no-values are fully supported.
Chunks can be uncompressed or compressed with a range of compression options, including wavelet compression (lossy or lossless), zipped, or run-length encoding. Constant value chunks are marked as such in the index of the dataset and do not need to be stored explicitly, so sparse volumes are represented in an efficient way.
The base brick size of a 3D brick is always a power-of-two (64, 128, 256 etc.), and bricks always have the same size in each dimension. 2D tiles have a size that is a multiple (usually 4 times) of the base brick size in order to reduce the overhead of having a lot of separate objects.
Chunk metadata
To enable sparse datasets to be efficiently represented, as well as chunk compression methods that can use adaptive/progressive compression (i.e. use a prefix of the serialized chunk data to produce a lower-quality version of the chunk), we can have a small amount of extra binary data (typically 8-40 bytes for each chunk) that are available as a 1D array divided into pages of a fixed number of chunk entries.
The interpretation of this chunk-metadata is dictated by the serialization method for the layer in question. The 8 first bytes is the volume data hash which is used to detect duplicates. It does not have to be a real hash of the data, the only requirement is that if the volume data hash of two chunks is identical we can assume the data stored for that chunk is the same. Chunk-metadata page entries with a value of 0 indicate a chunk has not been written, and this is not a legal volume data hash. There are special values of the volume data hash to indicate the whole chunk is NoValue (0xFFFFFFFFFFFFFFFF) or constant (first 4 bytes is an IEEE floating point value, next 4 bytes is 0x01010101). For wavelet compressed data a small table is stored in the next 16 bytes where each byte represents how many 255ths of the size of the previous level (starting with the size of the full object) are required in order to decompress that quality level.